Use Azure Backup Metrics to monitor the health of your backups in Azure
Use Metrics & Dimensions in your monitoring
You can use some built-in metrics via Azure Monitor that allows you to monitor the health of your backups. It also allows you to configure alert rules that trigger when the metrics exceed defined thresholds.
Some key capabilities with Azure Backup are:
- Out-of-the-box metrics related to back up and restore health of your environment
- Write custom alert rules on these metrics to efficiently monitor the health of your environment
- Route fired metric alerts to different notification channels supported by Azure Monitor, such as email, ITSM, webhook, logic apps, and many more.
Currently we have the following resource types that are supported with Azure Backup metrics.
- Azure VM, SQL databases in Azure VM
- SAP HANA databases in Azure VM
- Azure Files
- Azure Blobs.
Available metrics
We currently can work with two types of Metrics in Azure Backup
- Backup Health Events: The value of this metric represents the count of health events pertaining to backup job health, which were fired for the vault within a specific time. When a backup job completes, the Azure Backup service creates a backup health event. Based on the job status (such as succeeded or failed), the dimensions associated with the event vary.
- Restore Health Events: The value of this metric represents the count of health events pertaining to restore job health, which were fired for the vault within a specific time. When a restore job completes, the Azure Backup service creates a restore health event. Based on the job status (such as succeeded or failed), the dimensions associated with the event vary.
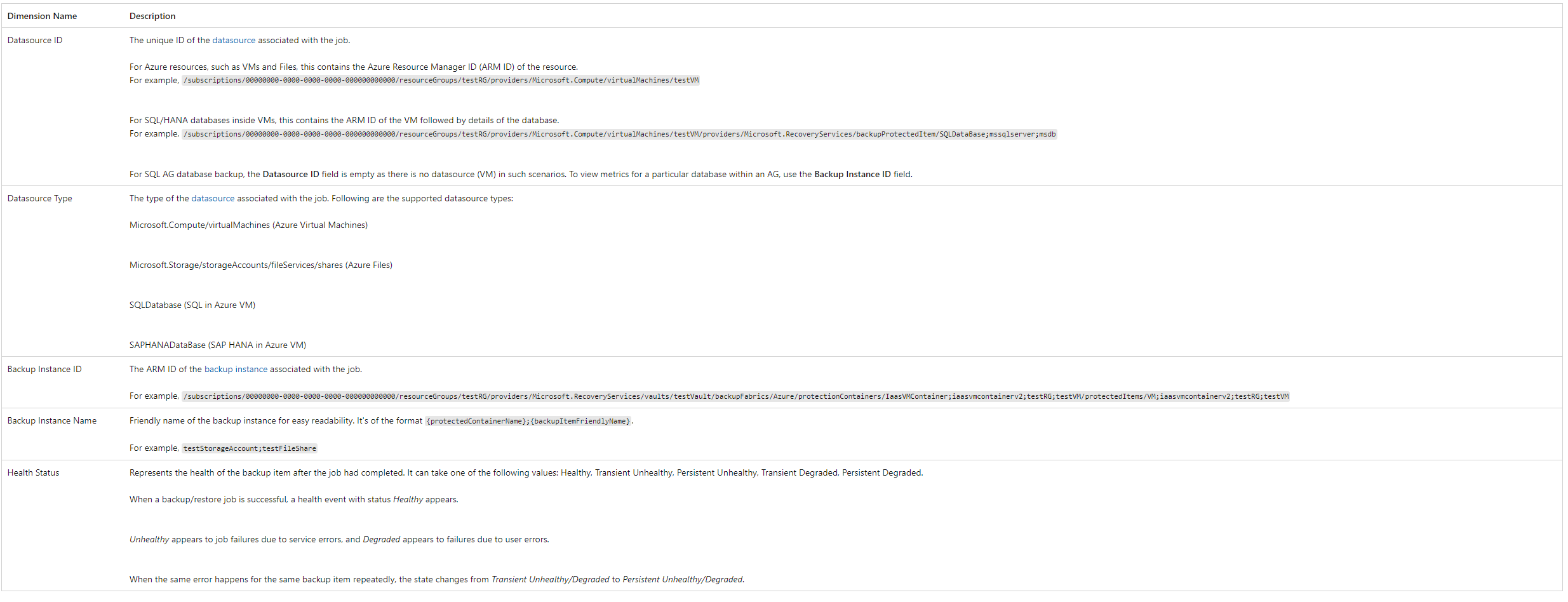
We have the following dimensions to work with:
Accessing metrics & dimensions
A note about access to certain dimensions in metrics is that if an event has not happened for the vault you are looking at it will not show up as a dimension. For example I was looking for the dimension Persistent Degraded in my vault but I could only find the dimension Healhty. Since this was a smaller vault that was running successfully I could only see healthy.
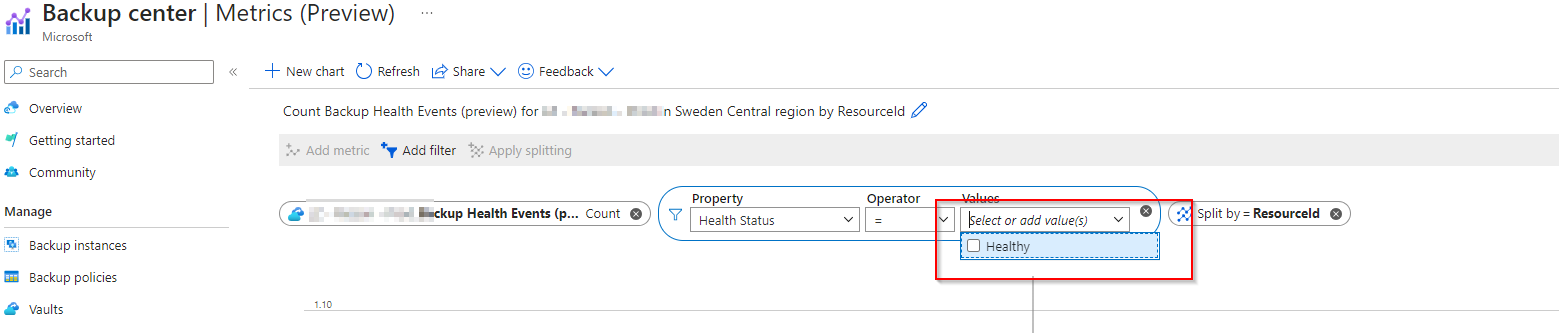
The dimension Persistent Degraded if you remember from the table above is a backup error that is occuring consecutively due to user error, like the VM agent is not online.
In another vault where this was the case I was able to see the correct dimension:
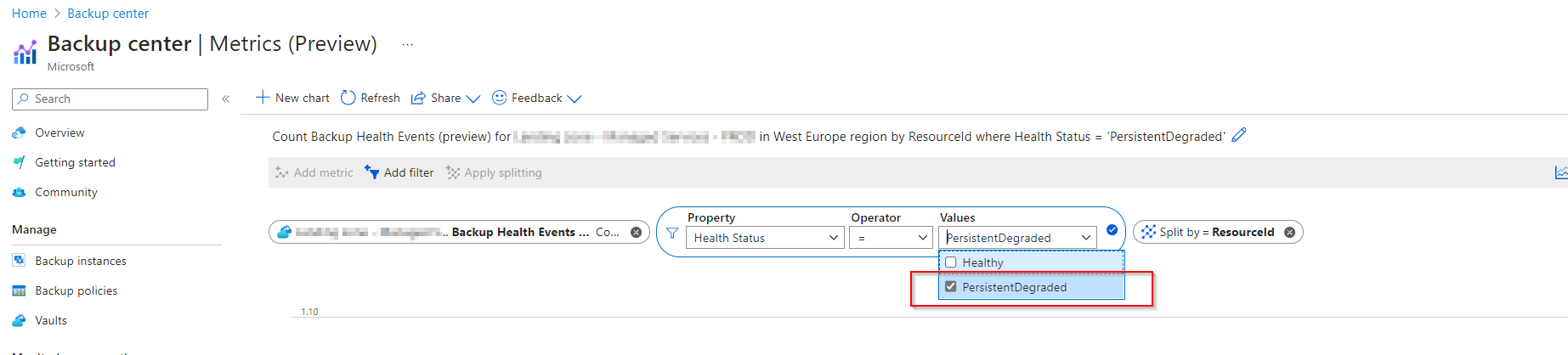
If this happens to you just go ahead and manually add the value, ensure you spell it correctly.
Build your alert
I am interested in PersistentDegraded & PersistentUnhealthy because if we have a repeated failure in backup I want to know about that and see if I can identity any patterns here.
So when I have built the logic I want simply create the alert rule:

Configure the logic to suit your needs and connect an Action Group to your alert and you're all set to go!
Conclusion
It is always important to get notified when backupjobs does not complete successfully. I really like that ability here as well to look for persistently failing jobs wether it's due to user error or something platform related.
This gives you the ability to also follow up on backup reports long term to identify any potential reoccuring problems you may have in the environment.
Hope you enjoyed!
References

About me
